 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecontextualization Mitigates Specification Gaming without Modifying the Specification
Dec 22, 2025Developers often struggle to specify correct training labels and rewards. Perhaps they don't need to. We propose recontextualization, which reduces how often language models "game" training signals, performing misbehaviors those signals mistakenly reinforce. We show recontextualization prevents models from learning to 1) prioritize evaluation metrics over chat response quality; 2) special-case code to pass incorrect tests; 3) lie to users; and 4) become sycophantic. Our method works by generating completions from prompts discouraging misbehavior and then recontextualizing them as though they were in response to prompts permitting misbehavior. Recontextualization trains language models to resist misbehavior even when instructions permit it. This mitigates the reinforcement of misbehavior from misspecified training signals, reducing specification gaming without improving the supervision signal.
Inoculation Prompting: Instructing LLMs to misbehave at train-time improves test-time alignment
Oct 06, 2025Large language models are sometimes trained with imperfect oversight signals, leading to undesired behaviors such as reward hacking and sycophancy. Improving oversight quality can be expensive or infeasible, motivating methods that improve learned behavior despite an imperfect training signal. We introduce Inoculation Prompting (IP), a simple but counterintuitive technique that prevents learning of an undesired behavior by modifying training prompts to explicitly request it. For example, to inoculate against reward hacking, we modify the prompts used in supervised fine-tuning to request code that only works on provided test cases but fails on other inputs. Across four settings we find that IP reduces the learning of undesired behavior without substantially reducing the learning of desired capabilities. We also show that prompts which more strongly elicit the undesired behavior prior to fine-tuning more effectively inoculate against the behavior when used during training; this serves as a heuristic to identify promising inoculation prompts. Overall, IP is a simple yet effective way to control how models generalize from fine-tuning, preventing learning of undesired behaviors without substantially disrupting desired capabilities.
Visualizing Neural Network Imagination
May 10, 2024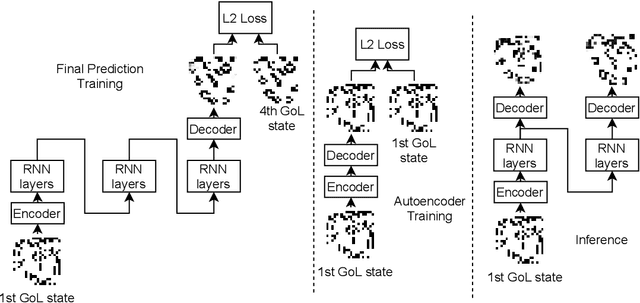
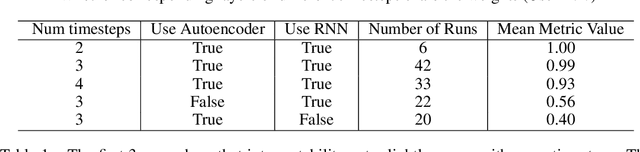


In certain situations, neural networks will represent environment states in their hidden activations. Our goal is to visualize what environment states the networks are representing. We experiment with a recurrent neural network (RNN) architecture with a decoder network at the end. After training, we apply the decoder to the intermediate representations of the network to visualize what they represent. We define a quantitative interpretability metric and use it to demonstrate that hidden states can be highly interpretable on a simple task. We also develop autoencoder and adversarial techniques and show that benefit interpretability.
Gradient-Based Language Model Red Teaming
Jan 30, 2024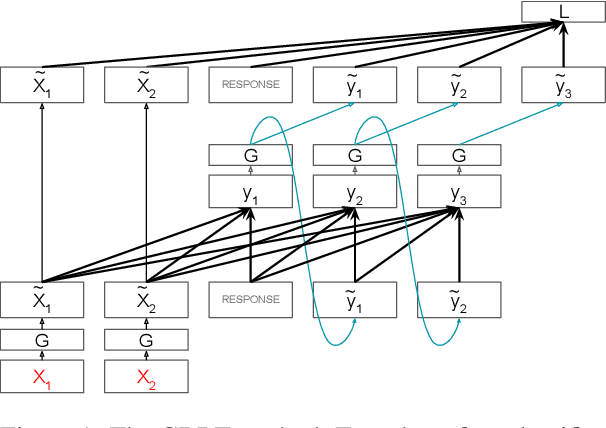

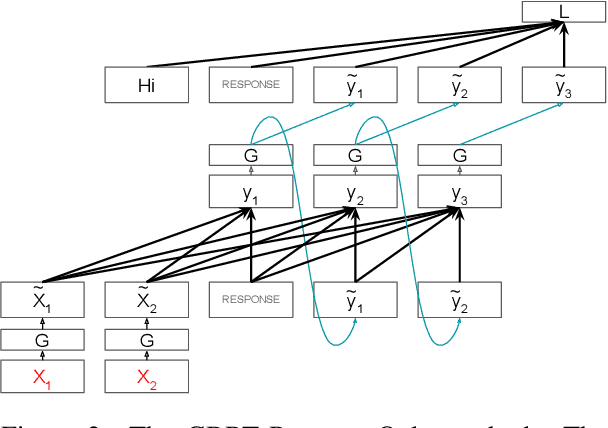
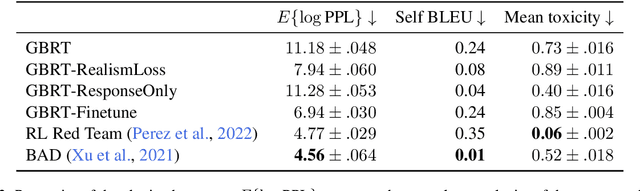
Red teaming is a common strategy for identifying weaknesses in generative language models (LMs), where adversarial prompts are produced that trigger an LM to generate unsafe responses. Red teaming is instrumental for both model alignment and evaluation, but is labor-intensive and difficult to scale when done by humans. In this paper, we present Gradient-Based Red Teaming (GBRT), a red teaming method for automatically generating diverse prompts that are likely to cause an LM to output unsafe responses. GBRT is a form of prompt learning, trained by scoring an LM response with a safety classifier and then backpropagating through the frozen safety classifier and LM to update the prompt. To improve the coherence of input prompts, we introduce two variants that add a realism loss and fine-tune a pretrained model to generate the prompts instead of learning the prompts directly. Our experiments show that GBRT is more effective at finding prompts that trigger an LM to generate unsafe responses than a strong reinforcement learning-based red teaming approach, and succeeds even when the LM has been fine-tuned to produce safer outputs.
DRLC: Reinforcement Learning with Dense Rewards from LLM Critic
Jan 14, 2024



Reinforcement learning (RL) can align language models with non-differentiable reward signals, such as human preferences. However, a major challenge arises from the sparsity of these reward signals - typically, there is only one reward for the entire generation. This sparsity of rewards can lead to inefficient and unstable learning. In this paper, we introduce a novel framework leveraging the critique ability of LLMs to produce dense rewards throughout the learning process. Our approach incorporates a critic language model alongside the policy model. This critic is prompted with the task description, question, policy model's output, and environment's reward signal as input, and provides token or span-level dense rewards that reflect the quality of each segment of the output. We assess our approach on three text generation tasks: sentiment control, language model detoxification, and summarization. Experimental results show that incorporating artificial dense rewards in training yields consistent performance gains over the PPO baseline with holistic rewards. Furthermore, in a setting where the same model serves as both policy and critic, we demonstrate that "self-critique" rewards also boost learning efficiency.
Fusion-Eval: Integrating Evaluators with LLMs
Nov 15, 2023
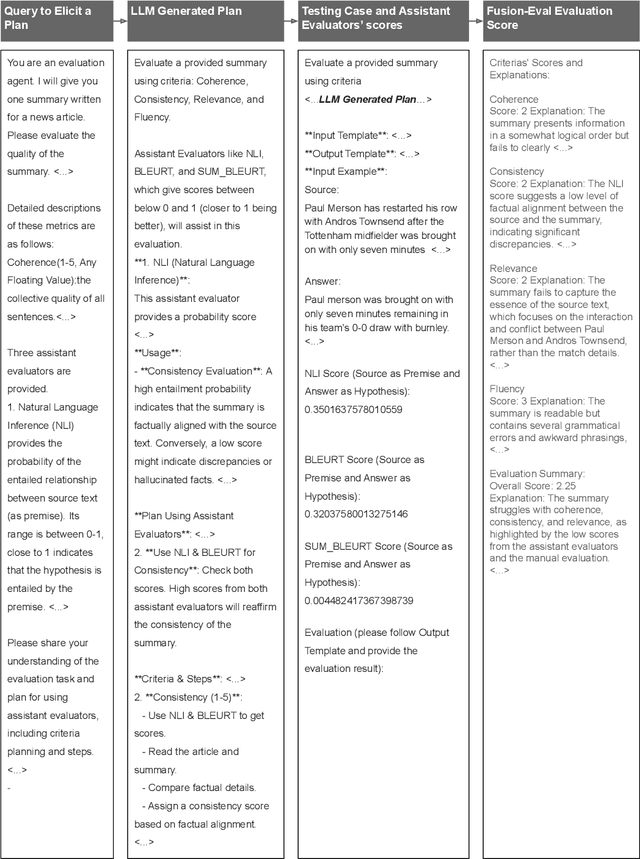
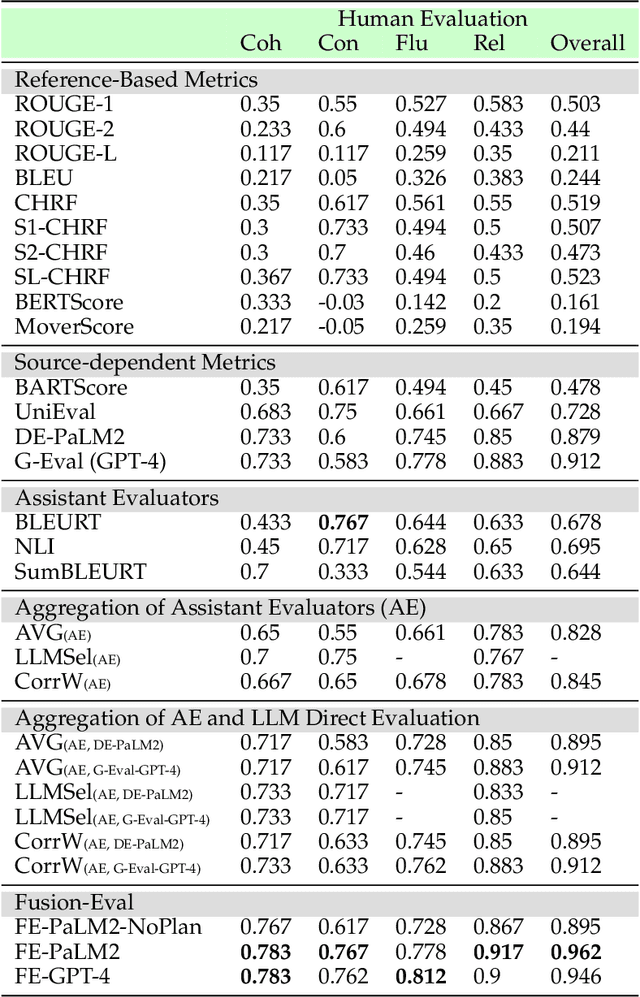
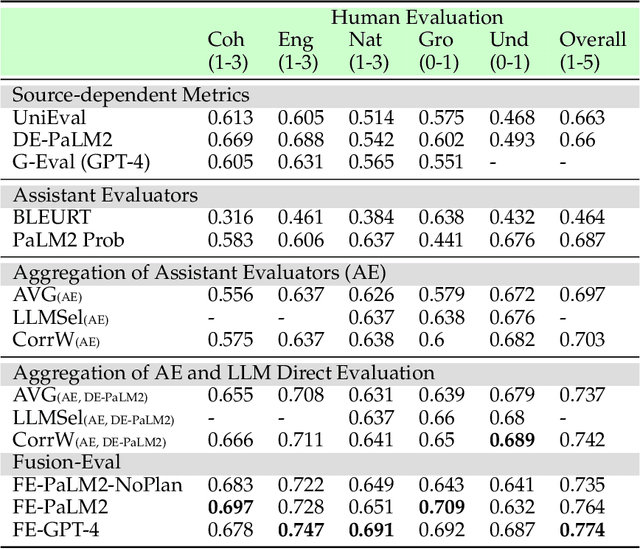
Evaluating Large Language Models (LLMs) is a complex task, especially considering the intricacies of natural language understanding and the expectations for high-level reasoning. Traditional evaluations typically lean on human-based, model-based, or automatic-metrics-based paradigms, each with its own advantages and shortcomings. We introduce "Fusion-Eval", a system that employs LLMs not solely for direct evaluations, but to skillfully integrate insights from diverse evaluators. This gives Fusion-Eval flexibility, enabling it to work effectively across diverse tasks and make optimal use of multiple references. In testing on the SummEval dataset, Fusion-Eval achieved a Spearman correlation of 0.96, outperforming other evaluators. The success of Fusion-Eval underscores the potential of LLMs to produce evaluations that closely align human perspectives, setting a new standard in the field of LLM evaluation.
SiRA: Sparse Mixture of Low Rank Adaptation
Nov 15, 2023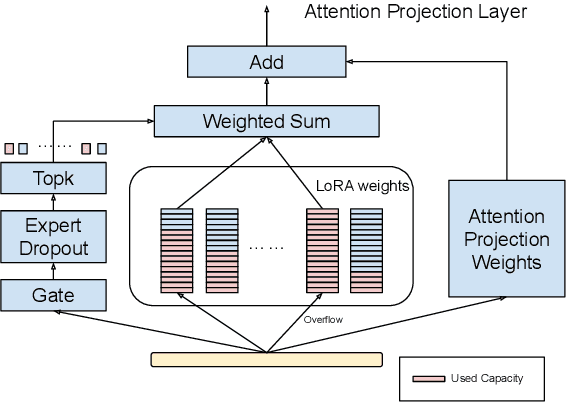



Parameter Efficient Tuning has been an prominent approach to adapt the Large Language Model to downstream tasks. Most previous works considers adding the dense trainable parameters, where all parameters are used to adapt certain task. We found this less effective empirically using the example of LoRA that introducing more trainable parameters does not help. Motivated by this we investigate the importance of leveraging "sparse" computation and propose SiRA: sparse mixture of low rank adaption. SiRA leverages the Sparse Mixture of Expert(SMoE) to boost the performance of LoRA. Specifically it enforces the top $k$ experts routing with a capacity limit restricting the maximum number of tokens each expert can process. We propose a novel and simple expert dropout on top of gating network to reduce the over-fitting issue. Through extensive experiments, we verify SiRA performs better than LoRA and other mixture of expert approaches across different single tasks and multitask settings.
SAFER: Data-Efficient and Safe Reinforcement Learning via Skill Acquisition
Feb 10, 2022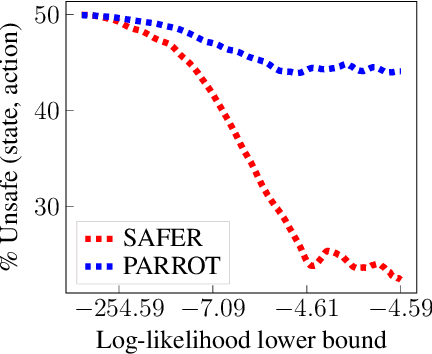
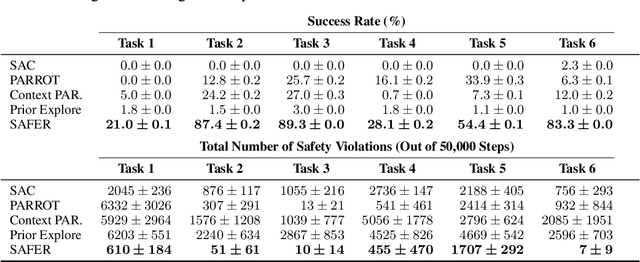
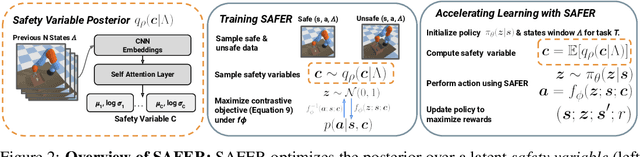
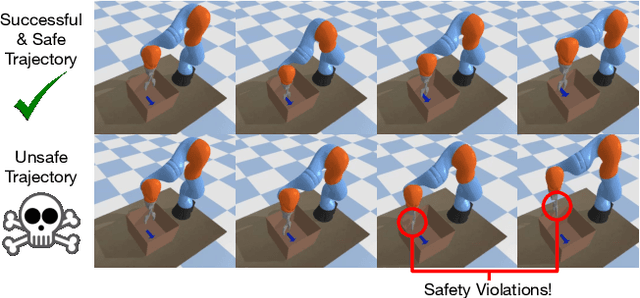
Though many reinforcement learning (RL) problems involve learning policies in settings with difficult-to-specify safety constraints and sparse rewards, current methods struggle to acquire successful and safe policies. Methods that extract useful policy primitives from offline datasets using generative modeling have recently shown promise at accelerating RL in these more complex settings. However, we discover that current primitive-learning methods may not be well-equipped for safe policy learning and may promote unsafe behavior due to their tendency to ignore data from undesirable behaviors. To overcome these issues, we propose SAFEty skill pRiors (SAFER), an algorithm that accelerates policy learning on complex control tasks under safety constraints. Through principled training on an offline dataset, SAFER learns to extract safe primitive skills. In the inference stage, policies trained with SAFER learn to compose safe skills into successful policies. We theoretically characterize why SAFER can enforce safe policy learning and demonstrate its effectiveness on several complex safety-critical robotic grasping tasks inspired by the game Operation, in which SAFER outperforms baseline methods in learning successful policies and enforcing safety.
ActionBert: Leveraging User Actions for Semantic Understanding of User Interfaces
Jan 25, 2021
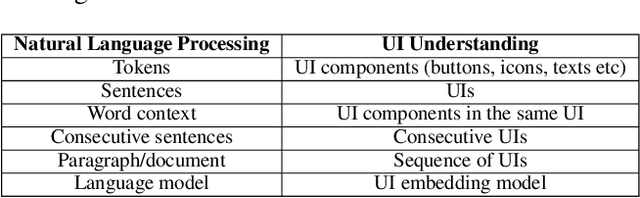
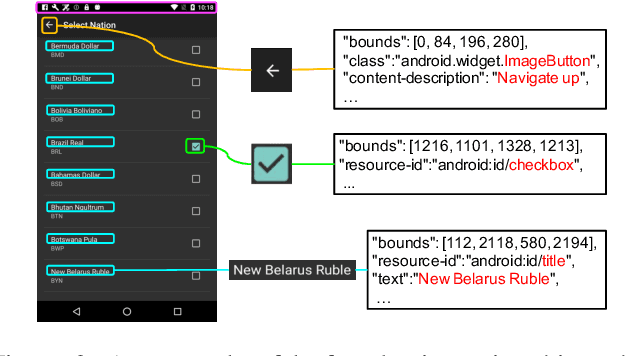
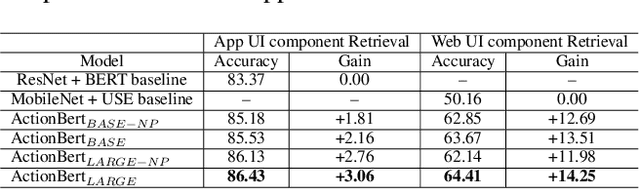
As mobile devices are becoming ubiquitous, regularly interacting with a variety of user interfaces (UIs) is a common aspect of daily life for many people. To improve the accessibility of these devices and to enable their usage in a variety of settings, building models that can assist users and accomplish tasks through the UI is vitally important. However, there are several challenges to achieve this. First, UI components of similar appearance can have different functionalities, making understanding their function more important than just analyzing their appearance. Second, domain-specific features like Document Object Model (DOM) in web pages and View Hierarchy (VH) in mobile applications provide important signals about the semantics of UI elements, but these features are not in a natural language format. Third, owing to a large diversity in UIs and absence of standard DOM or VH representations, building a UI understanding model with high coverage requires large amounts of training data. Inspired by the success of pre-training based approaches in NLP for tackling a variety of problems in a data-efficient way, we introduce a new pre-trained UI representation model called ActionBert. Our methodology is designed to leverage visual, linguistic and domain-specific features in user interaction traces to pre-train generic feature representations of UIs and their components. Our key intuition is that user actions, e.g., a sequence of clicks on different UI components, reveals important information about their functionality. We evaluate the proposed model on a wide variety of downstream tasks, ranging from icon classification to UI component retrieval based on its natural language description. Experiments show that the proposed ActionBert model outperforms multi-modal baselines across all downstream tasks by up to 15.5%.
RL agents Implicitly Learning Human Preferences
Feb 14, 2020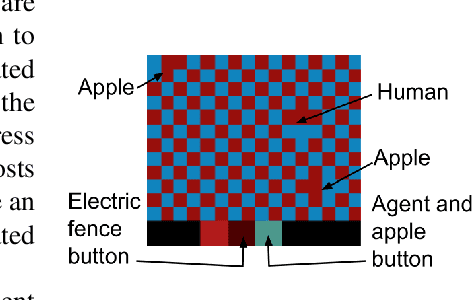
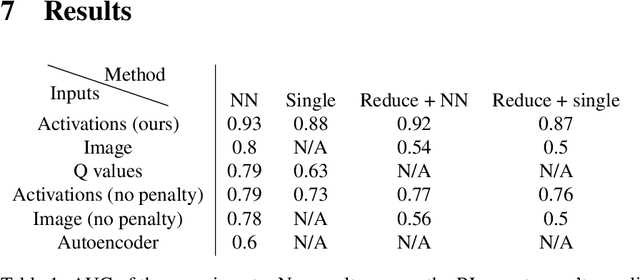
In the real world, RL agents should be rewarded for fulfilling human preferences. We show that RL agents implicitly learn the preferences of humans in their environment. Training a classifier to predict if a simulated human's preferences are fulfilled based on the activations of a RL agent's neural network gets .93 AUC. Training a classifier on the raw environment state gets only .8 AUC. Training the classifier off of the RL agent's activations also does much better than training off of activations from an autoencoder. The human preference classifier can be used as the reward function of an RL agent to make RL agent more beneficial for humans.